ETL vs ELT – What’s the difference and when to use each?
8 minutes reading
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two common methods for data integration and managing data pipelines. Both are used to collect, process, and load data into a central platform, but they differ in the order of operations and where transformations occur. In this article, we’ll clearly explain the basics of ETL and ELT, focusing on their differences, real-world examples, and when each method is best suited. We’ll also compare ETL and ELT techniques for businesses, exploring how each impacts data workflows, infrastructure, and overall performance. Whether you're working in food & beverage, manufacturing, fashion, equipment, or retail & logistics, understanding these concepts helps you build a modern data platform for analysis and decision-making.
What is ETL (Extract, Transform, Load)?
ETL is the traditional process for extracting data from source systems, transforming it using business logic, and then loading the cleaned and structured data into a data warehouse for analysis. In ETL, the transformation step takes place before the data is loaded into the target system.
Example of ETL
A manufacturing company extracts daily order and inventory data from its ERP system, applies transformations like currency conversion, data cleansing, and merging tables, then loads the processed data into a central data warehouse. Once loaded, it's ready for reporting in tools like Power BI or Qlik.
Advantages of ETL
- Ensures data quality before loading
- Useful when strict validation or privacy (e.g. GDPR) is required
- Good for structured data and legacy systems
Drawbacks of ETL
- Can be time-consuming for large datasets
- Requires transformation logic to be predefined
- Involves more complex infrastructure (ETL tools, staging areas)
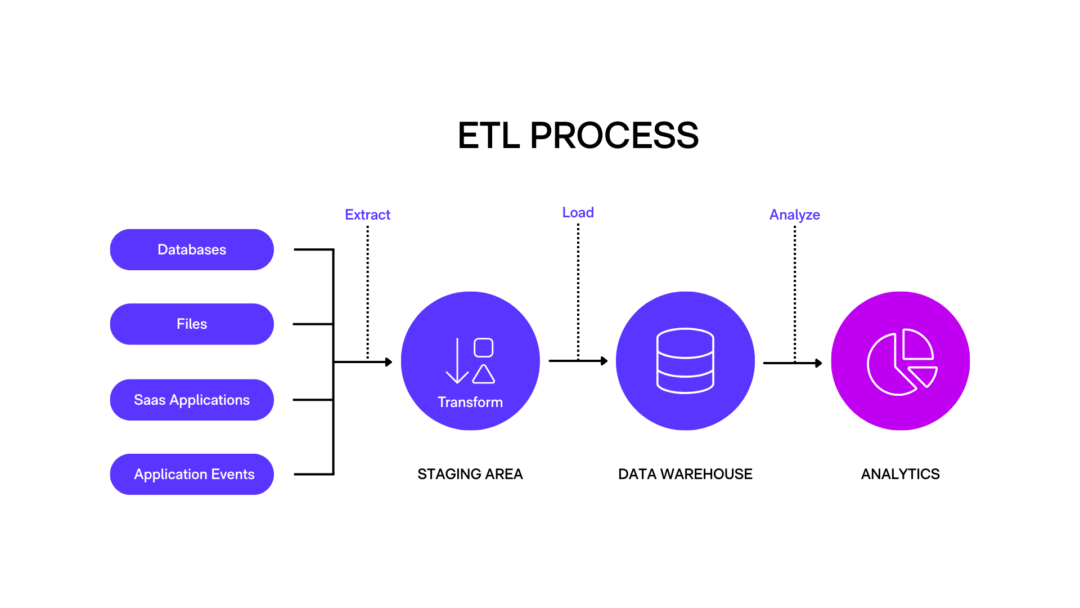
What is ELT (Extract, Load, Transform)?
ELT is a modern alternative to ETL. Here, data is first extracted and loaded into the target system, typically a cloud-based data warehouse or data lake. The transformation step happens after the data is loaded, directly inside the platform using tools like SQL, Spark, or built-in warehouse features.
Example of ELT
A retail company gathers large volumes of sales data, website analytics, and IoT sensor logs. With ELT, all raw data is ingested into a cloud data lake. Then, transformations like filtering, aggregation, and joins are done within the warehouse - depending on current needs.
Advantages of ELT
- Highly flexible – raw data is retained and can be reused
- Great for large volumes and semi-structured data (e.g. JSON, logs)
- Simplifies architecture - fewer tools, faster ingestion
Drawbacks of ELT
- Requires powerful data platforms (cloud data warehouses)
- Governance and data quality must be handled post-load
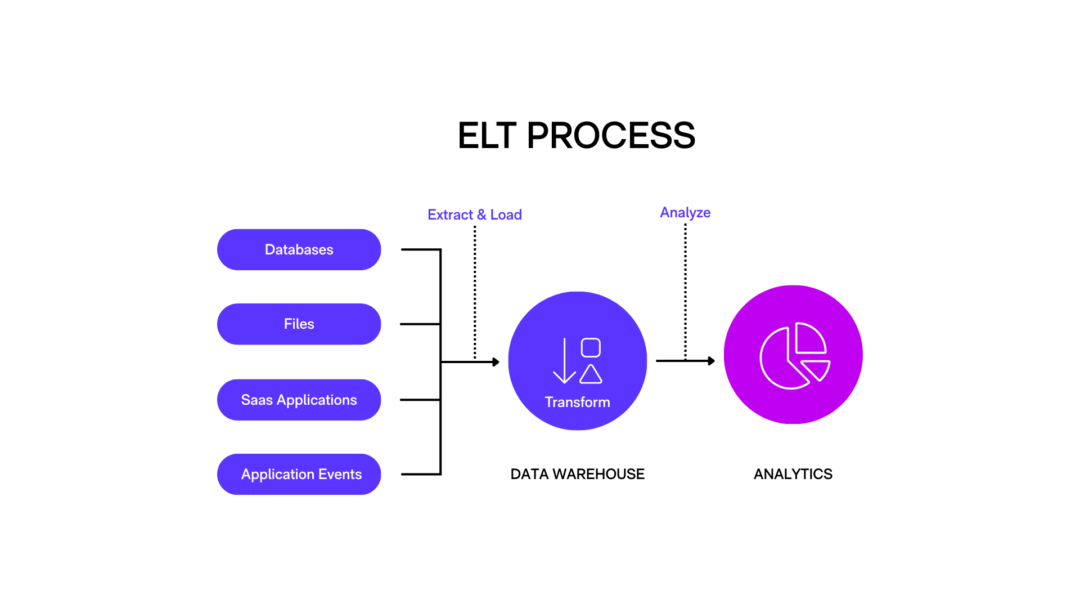
Differences between ETL and ELT
Both ETL and ELT aim to create a common data foundation for BI and analytics, but they have important differences. Below are some key differences between the two approaches:
- Process order: ETL transforms data before it is loaded into the target system, whereas ELT transforms data after it has been loaded. With ETL, the schema (structure) is written at the time of writing, while ELT applies structure only when reading data (sometimes called schema-on-read).
- Infrastructure & location for transformation: In ETL, the transformation occurs in a secondary environment or a separate ETL tool/server outside the target platform. In ELT, the transformation takes place directly in the target data lake/database, without intermediaries. This means that the ELT architecture has fewer moving parts, while the ETL architecture can be more complex with staging areas and intermediary storage tables.
- Data types & volumes: ETL is well suited for structured data from e.g. relational databases and business systems, where you know in advance which fields and tables are needed. ELT can also handle semi-structured and unstructured data (e.g. JSON files, images, sensor data) by first storing them raw and then transforming them as needed. For very large data volumes (e.g. millions of rows per day or petabytes of data), ELT often scales better, as it avoids the extra step of transforming everything before loading – instead, transformations can occur gradually and in parallel afterwards.
- Performance & speed: Generally, ELT is faster for handling large data volumes, as data can be loaded quickly and then processed using the power of modern databases (massively parallel processing in the cloud). ETL can become slow if the data volume increases, as the extra transformation step before loading can become a bottleneck. On the other hand, ETL can be efficient for smaller datasets or when transformations are very complex but the data volume is relatively small.
- Cost & complexity: ETL projects often require more initial planning - you must define the target format, data mappings and business rules in advance, and sometimes invest in separate ETL tools or servers. This means that the time and cost to set up ETL can be higher. ELT can, in many cases, simplify the chain by leveraging existing cloud infrastructure; fewer systems to maintain can mean lower costs and simpler processes. However, it should be noted that cloud storage and computation also incur costs - ELT shifts the cost to the data warehouse environment instead of an ETL tool.
- Data quality & governance: With ETL, you have the opportunity to validate and cleanse data upstream before it is written to the target data lake. For example, you can implement business rules that stop erroneous data entries, perform matching and data cleansing, so that only high-quality data lands in the lake. ELT means that even raw data (including potential inaccuracies) is stored first, and quality assurance is achieved through subsequent transformations and checks. This requires good data governance practices - e.g. incorporating quality tests into the SQL scripts or pipelines that perform the transformations, ensuring that the data ultimately used in reports is accurate.
- Security & compliance: ETL can facilitate the handling of sensitive information, as you can exclude or mask personal data before it leaves the source system. Only necessary and approved data fields are included, making GDPR and HIPAA compliance easier in some cases. In an ELT approach, often all raw data is loaded in, which requires the target data lake to have robust security features (access control, encryption, etc.). Modern cloud solutions, however, offer fine-grained permissions and built-in security that can handle this, ensuring that even raw data is properly protected on the platform.
Main differences between ETL and ELT
| Feature | ETL | ELT |
| Order of steps | Extract → Transform → Load | Extract → Load → Transform |
| Where transformation happens | Outside the destination (ETL tool) | Inside the destination (e.g. Snowflake) |
| Best for | Structured, known data | Large, flexible, or unstructured data |
| Data volume handling | Slower at scale | Better scalability with cloud tools |
| Control & Quality | High control before load | Needs careful governance after load |
| Infrastructure | Requires separate ETL tooling | Cloud-native, streamlined setup |
| Compliance | Easier to filter sensitive data early | Depends on warehouse security features |
When to use ETL versus ELT?
A rule of thumb today is that ELT has become the standard choice for many modern cloud analytics platforms. Collecting all data first and later deciding how to use it provides flexibility, especially when companies in retail or logistics, for example, generate large amounts of various kinds of data. Cloud-based data warehousing services (such as Snowflake, Azure Synapse, Google BigQuery, etc.) are designed for ELT and can handle both structured and unstructured data at scale. If your organization is investing in cloud data integration and wants to create a "single source of truth" for all your information, ELT is often the right way to go. For instance, a food company with IoT sensors in the factory and sales data from stores may choose to stream all raw sensor information to a cloud platform and then transform it there for advanced analytical purposes (e.g., predictive maintenance or quality control), while the sales data might take a more traditional ETL route into a reporting layer for daily KPI reports. Combinations often occur in practice – one may use ETL for certain sources and ELT for others within the same organization, depending on needs.
However, there are situations where ETL is better suited or needed as a complement:
- Limited data volumes and clear requirements: If the data volume is relatively small or well-defined, and one knows in advance exactly which transformations are required (e.g., consolidating financial data from two systems after a company merger), ETL may be easier to implement. You get a quick, ready foundation for a specific use, and any sensitive information can be handled before being uploaded. ETL is often used for legacy systems or older business systems where the structure is fixed and only a slice of the data is needed.
- High demands for real-time data quality: In operations that require very high data quality at all times – such as in fashion or food where incorrect product data can lead to costly decisions – ETL may be preferred for the core data store. By validating and cleansing data early, the spread of errors is avoided. (Note that even with ELT, quality can be maintained, but it is done through rigorous checks afterwards.)
- Experimentation and ad-hoc analysis: Data engineers sometimes experiment or perform one-off analyses on new data sources. There, a quick ETL process can help extract and transform data to see if it is useful, without first integrating all raw material into the platform. If the experiment goes well, one can then upload larger quantities and perhaps switch to ELT for the full-scale solution.
- Limitations in the target system: If the target data store (the database) is not powerful enough or if one is working on-premises without scalable cloud capacity, classic ETL may be necessary. For example, in some manufacturing companies with older SQL data warehouses, it may not be possible to store years of raw sensor logs. In such cases, one only extracts key indicators or aggregated data via ETL to avoid overloading the warehouse.
- Edge computing and IoT: In scenarios with, for example, connected machines and sensors (common in equipment and manufacturing industries), some preprocessing at the source (ETL at the edge) may be desirable. An example is filtering and compressing sensor streams: instead of sending each individual data point to the cloud, an edge device can perform ETL-like aggregations (e.g., calculating averages, removing noise) and then send the processed information at a lower frequency. This reduces the data volumes transferred and stored centrally, while retaining essential information for analysis.
In summary, there is no universal solution where either ETL or ELT is always best – it depends on your data environment, your tools, and goals. ELT is trending strongly with the advance of the cloud, thanks to the flexibility and scalability to handle everything from structured business systems to unstructured big data on a single platform. At the same time, ETL plays an important role when strict control over data is needed before loading or when working with systems that cannot handle heavy post-processing. In many cases, the two complement each other. By understanding the basics of ETL and ELT, IT leaders in industries such as food, manufacturing, and retail can design robust data flows tailored to their needs – whether it's a traditional data warehouse for reporting or a modern, cloud-based data lake solution for advanced analysis. With the right method at the right time, you build a reliable and efficient data infrastructure that enables insight-driven decisions across the organization.
FAQ
Frequently asked questions about ETL and ELT
Yes, combining ETL and ELT is common in real-world data architectures. You might use ETL for sensitive or legacy data that needs pre-processing and ELT for high-volume or flexible analytics use cases. The right mix depends on your data sources, infrastructure, compliance needs, and the analytical goals of your organization.
ELT typically offers better performance in cloud environments, where the data warehouse can perform transformations in parallel using its native compute power. ETL might become a bottleneck with large datasets due to the extra transformation step before loading. However, for small to medium volumes and well-defined transformations, ETL can be just as fast and more predictable.
ELT is ideal when working with large-scale, diverse datasets - especially semi-structured or unstructured data like logs or sensor data. It offers flexibility for future use cases and leverages the power of modern cloud data warehouses to transform data after loading. ELT is often preferred for scalable, cloud-based data architectures.
The key difference lies in the order of operations. ETL transforms data before loading it into the destination system, while ELT transforms data after it has been loaded. In practice, this means ETL is often used when data needs to be cleaned or structured in advance, whereas ELT works best in modern cloud platforms that can handle raw data and process it internally.
ETL is the better choice when you’re dealing with structured data from systems like ERP or CRM, when strict data quality is required before storage (e.g. for compliance), or when your destination system doesn’t have the capacity to transform large volumes of data efficiently. It’s also useful when transformation logic is clearly defined and doesn’t change often.
Ready for the next step towards becoming a more data-driven organisation?
{kind=link}
Related news
Why AI adoption in organisations often gets stuck between tools and vision

When transport planning becomes a bottleneck in production
