ETL vs ELT – vad är skillnaden och när ska man använda vilken?
8 minuter läsning
ETL (Extract, Transform, Load) och ELT (Extract, Load, Transform) är två vanliga metoder för dataintegration och hantering av data pipelines. Båda används för att samla, bearbeta och ladda data till en central plattform, men de skiljer sig åt i ordningen på stegen och var transformationen sker. I den här artikeln förklarar vi grunderna i ETL och ELT, med fokus på skillnaderna, praktiska exempel och när respektive metod passar bäst. Oavsett om du arbetar med data inom livsmedel, tillverkning, mode, utrustning eller retail & logistik, hjälper dessa koncept dig att bygga en modern dataplattform för analys och beslutstöd.
Vad är ETL (Extract, Transform, Load)?
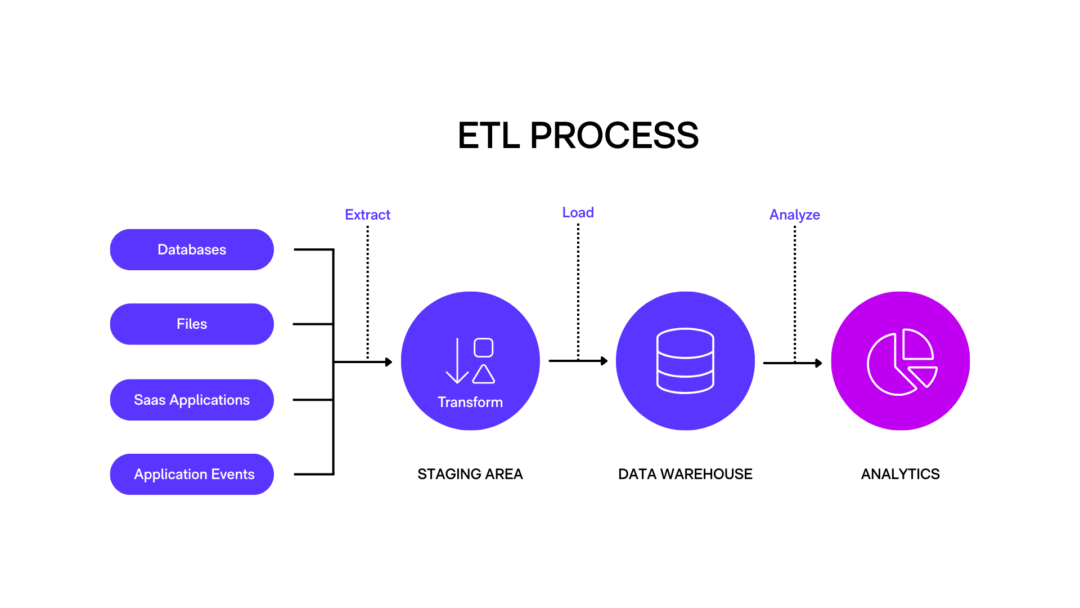
ETL är den traditionella processen för att extrahera data från källsystem, transformera (omvandla) den enligt behov, och sedan ladda in den i ett målsystem (ofta ett data warehouse, dvs. datalager för analys). Transformationen sker innan datan lagras i målsystemet. Detta innebär att data tvättas, filtreras och struktureras i förväg med hjälp av ett specialiserat ETL-verktyg eller en motor, och resultatet som laddas är redan anpassat efter målsystemets struktur.
Ett konkret exempel på ETL: ett företag inom tillverkningsindustrin kan dagligen extrahera affärsdata från sitt ERP-system (t.ex. order- och lagerinformation), använda affärsregler för att rensa och konsolidera dessa data (t.ex. filtrera bort felaktiga poster, konvertera valuta, sammanfoga tabeller), för att slutligen ladda in den bearbetade informationen i ett centralt datalager. När datan väl finns i datalagret är den färdigstrukturerad för analys i exempelvis Power BI eller Qlik.
Fördelarna med ETL är att man på förhand säkerställer datakvalitet - man kan validera, deduplicera och transformera informationen innan den landar i målsystemet. Detta minskar risken för inkonsekvenser och underlättar efterlevnad av regelverk, eftersom man kan välja bort eller anonymisera känslig data redan innan laddning (t.ex. för GDPR).
En möjlig nackdel är att ETL-processen kan vara tidskrävande för mycket stora datamängder, då all transformation sker innan laddning. Traditionellt begränsade även lagringskostnader och prestanda hur mycket rådata man hade råd att spara, vilket gjorde ETL till ett naturligt val – man tog bara med det som behövdes och i format som passade måldatalagret.
Vad är ELT (Extract, Load, Transform)?
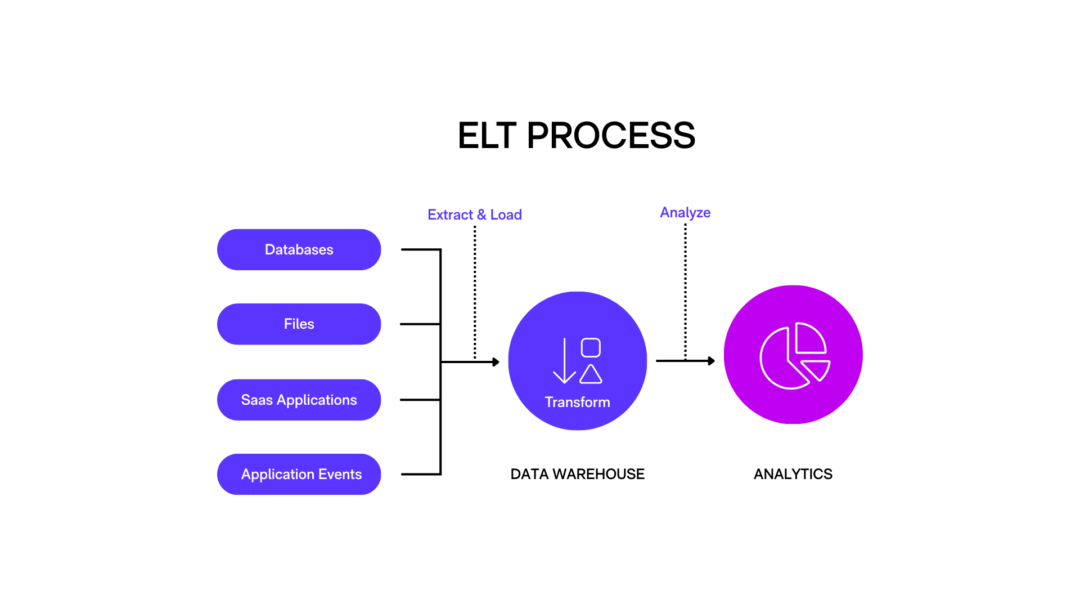
ELT är en modern variation av ETL där ordningen på de sista stegen är omvänd - man extraherar först data från källor, laddar därefter omedelbart all rådata till målsystemet, och utför transformationerna i detta målsystemgraz.se. Med ELT sparar man alltså först data i originalformat (ofta i en molnbaserad datalagring som ett data lake eller cloud data warehouse) och omvandlar den vid behov för analys. Skillnaden mot ETL är främst var och när datan bearbetas: i en ELT-pipeline sker omvandlingen efter inladdning och utnyttjar måldatalagrets egna bearbetningskraft. Detta förenklar arkitekturen genom att eliminera behovet av en separat transformationsmotor.
Med andra ord kan man använda databashanterarens eller dataplattformens inbyggda funktioner (t.ex. SQL, Hadoop/Spark) för att filtrera, aggreggera och modellera datan direkt i lagringsmiljön.
Ett exempel på ELT är en retailkedja med omfattande e-handels- och sensordata: istället för att i förväg bestämma exakt vilka data som behövs, kan man löpande ladda upp alla transaktionsloggar, webbanalysdata och IoT-sensordata till en skalbar data lake i molnet. Först efter att datan lagrats kan dataingenjörer eller analytiker transformera och kombinera relevanta delar - exempelvis sammanställa försäljningssiffror med webbtrafik och lagerstatus - direkt i måldatalagret för att få affärsinsikter.
Fördelen med ELT är att det ger maximal flexibilitet och framtidssäkring: rådata finns kvar och kan återanvändas eller omformas på olika sätt för olika användningsfall. Dessutom kan moderna molnplattformar hantera stora datavolymer och komplexa frågor med hög prestanda, vilket gör att transformationer kan ske snabbare genom parallell bearbetning i databasen.
ELT lämpar sig särskilt väl för stora dataflöden och ostrukturerad data - t.ex. loggfiler, bilder eller dokument - som tidigare var svåra att integrera i traditionella datalager. Observera dock att ELT förutsätter ett kraftfullt målsystem; prestandan och skalbarheten i databasen eller data-lösningen är avgörande för att kunna transformera data effektivt på detta sätt.
Skillnader mellan ETL och ELT
Både ETL och ELT syftar till att skapa en gemensam datagrund för BI och analys, men de har viktiga skillnader. Nedan sammanfattas några nyckelskillnader mellan de två angreppssätten:
- Processordning: ETL transformerar data innan den laddas in i målsystemet, medan ELT transformerar data efter att den laddats in. Med ETL skrivs alltså schemat (strukturen) vid skrivtillfället, medan ELT tillämpar struktur först vid läsning av data (ibland kallat schema-on-read).
- Infrastruktur & plats för transformering: I ETL sker transformationen i en sekundär miljö eller ett separat ETL-verktyg/server utanför målplattformen. I ELT sker transformationen direkt i måldatalagret/databasen, utan mellanhänder. Detta gör att ELT-arkitekturen har färre rörliga delar, medan ETL-arkitekturen kan vara mer komplex med staging-ytor och mellanlagringstabeller.
- Datatyper & volymer: ETL passar bra för strukturerad data från t.ex. relationsdatabaser och affärssystem, där man på förhand vet vilka fält och tabeller som behövs. ELT hanterar även semi-strukturerad och ostrukturerad data (t.ex. JSON-filer, bilder, sensordata) genom att först lagra dem råa och sedan omvandla vid behov. För väldigt stora datamängder (t.ex. miljontals rader per dag eller petabytes av data) skalar ELT ofta bättre, eftersom man slipper det extra steget att transformera allt innan laddning – istället kan transformationer ske gradvis och parallellt i efterhand.
- Prestanda & hastighet: Generellt är ELT snabbare för att hantera stora datavolymer, då datan snabbt kan laddas in och sedan bearbetas med hjälp av kraften i moderna databaser (massivt parallellbearbetning i molnet). ETL kan bli långsamt om datamängden växer, eftersom det extra transformationssteget före inladdning kan bli en flaskhals. Å andra sidan kan ETL vara effektivt för mindre dataset eller när transformationerna är mycket komplexa men datamängden relativt liten.
- Kostnad & komplexitet: ETL-projekt kräver ofta mer initial planering - man måste definiera målformat, datamappningar och affärsregler i förväg, och ibland investera i separata ETL-verktyg eller servrar. Detta gör att tidsåtgång och kostnad för att sätta upp ETL kan vara högre. ELT kan i många fall förenkla kedjan genom att utnyttja befintlig molninfrastruktur; färre system att underhålla kan innebära lägre kostnader och enklare. Notera dock att molnlagring och beräkning också kostar - ELT flyttar kostnaden till data warehouse-miljön istället för ett ETL-verktyg.
- Datakvalitet & styrning: Med ETL har man möjlighet att validera och rengöra data uppströms innan den skrivs till måldatalagret. Man kan t.ex. implementera affärsregler som stoppar felaktiga dataposter, utföra matchning och data cleansing, så att endast högkvalitativ data landar i lagret. ELT innebär att även rådata (inklusive eventuellt felaktigheter) lagras först, och kvalitetssäkringen sker genom efterföljande transformationer och kontroller. Detta kräver god praxis för data governance – t.ex. att man bygger in kvalitetstester i de SQL-skript eller pipelines som gör transformationerna, så att den data som slutligen används i rapporter är korrekt.
- Säkerhet & regelefterlevnad: ETL kan underlätta hantering av känslig information, då man kan exkludera eller maskera personuppgifter innan data lämnar källsystemet. Endast nödvändiga och godkända datafält tas med, vilket gör GDPR- och HIPAA-anpassning enklare i vissa fall. I en ELT-approach laddas ofta all rådata in, vilket ställer krav på att måldatalagret har robusta säkerhetsfunktioner (åtkomstkontroll, kryptering, etc.). Moderna cloud-lösningar erbjuder dock finkorniga behörigheter och inbyggd säkerhet som kan hantera detta, så att även rådata skyddas på rätt sätt i plattformen.
Huvudskillnader mellan ETL och ELT
| Egenskap | ETL | ELT |
| Ordning på stegen | Extrahera → Transformera → Ladda | Extrahera → Ladda → Transformera |
| Var sker transformationen? | Utanför målsystemet | I målsystemet (t.ex. molndatalager) |
| Typ av data | Strukturerad data | Strukturerad, semi-strukturerad, ostrukturerad |
| Prestanda | Långsammare för stora datamängder | Snabbare vid stora datavolymer |
| Flexibilitet | Begränsad – transformation styrs i förväg | Hög – transformation sker när behov uppstår |
| Datakvalitet | Hög kontroll innan lagring | Kräver tydlig governance efter lagring |
| Kostnad | Infrastruktur utanför målsystemet | Bygger på molnplattformens kapacitet |
När ska man använda ETL respektive ELT?
En tumregel idag är att ELT har blivit standardvalet för många moderna analysplattformar i molnet. Att först samla all data och senare bestämma hur den ska användas ger flexibilitet, särskilt när företag inom t.ex. retail eller logistik genererar stora mängder data av olika slag. Molnbaserade data warehousing-tjänster (som Snowflake, Azure Synapse, Google BigQuery m.fl.) är utformade för ELT och kan hantera både strukturerad och ostrukturerad data. Om din organisation satsar på cloud data integration och vill skapa en “single source of truth” för all er information, är ELT oftast rätt väg. Exempelvis kan ett livsmedelsföretag med IoT-sensorer i fabriken och försäljningsdata från butiker välja att strömma all rå sensorinformation till en molnplattform och sedan transformera den där för avancerade analysändamål (t.ex. förutsägande underhåll eller kvalitetskontroll), samtidigt som försäljningsdatan kanske går en mer traditionell ETL-väg in i ett rapporteringslager för dagliga KPI-rapporter. Kombinationer förekommer ofta i praktiken - man kanske använder ETL för vissa källor och ELT för andra inom samma organisation, beroende på behoven.
Det finns dock situationer där ETL lämpar sig bättre eller behövs som komplement:
- Begränsade datavolymer och tydliga krav: Om datamängden är relativt liten eller väl avgränsad, och man i förväg vet exakt vilka transformationer som krävs (t.ex. konsolidering av finansiella data från två system efter en företagsfusion), kan ETL vara enklare att implementera. Man får ett snabbt, färdigt underlag för en specifik användning, och eventuell känslig information kan hanteras innan den laddas upp. ETL används ofta för legacy-system eller äldre affärssystem där strukturen är fast och man bara behöver ett utsnitt av datan.
- Höga krav på datakvalitet i realtid: I verksamheter som kräver väldigt hög datakvalitet i alla lägen – till exempel inom mode eller livsmedel där felaktiga produktdata kan leda till kostsamma beslut – kan ETL vara att föredra för kärndatastore. Genom att validera och rengöra data tidigt undviks att fel sprids. (Notera att även vid ELT kan man upprätthålla kvalitet, men det sker genom rigorösa kontroller i efterhand.)
- Experiment och ad-hoc analys: Dataingenjörer gör ibland experiment eller engångsanalys på nya datakällor. Där kan en snabb ETL-process hjälpa till att extrahera och transformera data för att se om den är användbar, utan att först integrera allt råmaterial i plattformen. Om experimentet faller väl ut kan man sedan ladda upp större mängder och kanske gå över till ELT för den fullskaliga lösningen.
- Begränsningar i målsystemet: Om måldatalagret (databasen) inte är tillräckligt kraftfullt eller om man jobbar on-premises utan skalbar molnkapacitet, kan klassisk ETL vara nödvändigt. Till exempel, i vissa tillverkningsföretag med äldre SQL-datalager kanske det inte är möjligt att lagra år av rå sensorloggar. Då extraherar man bara nyckelindikatorer eller aggregerad data via ETL för att inte överbelasta lagret.
- Edge computing och IoT: I scenarier med t.ex. uppkopplade maskiner och sensorer (vanligt i utrustnings- och tillverkningsbranschen) kan viss förbehandling vid källan (ETL vid kanten) vara önskvärd. Ett exempel är att filtrera och komprimera sensorströmmar: i stället för att skicka varje enskild datapunkt till molnet, kan en edge-enhet göra ETL-liknande aggregeringar (t.ex. beräkna medelvärden, ta bort brus) och sedan skicka upp den bearbetade informationen med lägre frekvens. Detta minskar datavolymerna som överförs och lagras centralt, men behåller väsentlig information för analys.
Sammanfattningsvis finns det ingen universallösning där antingen ETL eller ELT alltid är bäst - det beror på din datamiljö, era verktyg och mål. ELT trendar starkt i och med molnets framfart, tack vare flexibiliteten och skalbarheten att hantera allt från strukturerade affärssystem till ostrukturerade big data i en enda plattform. Samtidigt fyller ETL en viktig roll när man behöver strikt kontroll på data innan laddning eller arbetar med system som inte klarar av tung efterhandsbearbetning. I många fall kompletterar de två varandra. Genom att förstå grunderna i ETL och ELT kan IT-ansvariga inom branscher som livsmedel, tillverkning och retail utforma robusta dataflöden anpassade efter just deras behov – vare sig det handlar om ett traditionellt data warehouse för rapportering eller en modern, molnbaserad data lake-lösning för avancerad analys. Med rätt metod vid rätt tillfälle bygger du en pålitlig och effektiv datainfrastruktur som möjliggör insiktsdrivna beslut i hela organisationen.
FAQ
Vanliga frågor om ETL och ELT
Ja, det är vanligt att kombinera dem. Vissa datakällor kan behöva förbehandlas via ETL innan laddning, medan annan data laddas direkt med ELT. Det viktiga är att anpassa strategin efter datans natur, affärsbehov och den tekniska miljön.
ELT ger ofta bättre prestanda i molnbaserade miljöer där databasen kan köra transformationer parallellt. ETL kan däremot bli långsamt om transformationssteget är tungt och sker innan laddning. Men med mindre datamängder och enkel logik fungerar ETL fortfarande snabbt och effektivt.
ELT är ofta bättre när du arbetar med stora datamängder, semi- eller ostrukturerad data (som loggar, sensordata), eller vill kunna omforma datan för olika syften i efterhand. Det kräver dock att du har en kraftfull molnplattform som kan hantera transformationer internt.
Den stora skillnaden är ordningen: ETL transformerar data innan den lagras, ELT gör det efter. I praktiken betyder det att ETL passar bättre när datan måste städas först, medan ELT fungerar bäst i moderna molnplattformar där man kan hantera stora mängder rådata direkt.
Använd ETL när du har tydligt definierade databehov, arbetar med strukturerad data från t.ex. affärssystem, eller när datan måste kvalitetssäkras innan den lagras – t.ex. för GDPR. ETL passar också bättre i miljöer där målsystemet har begränsad kapacitet.
Redo för nästa steg mot en mer datadriven organisation?
{kind=link}
Relaterade nyheter

Datastrategi: Vad är det, varför det är viktigt och så du kommer igång

Swedish Match Industries tar nästa digitala steg med Elvenite och Infor CloudSuite
